


Ce qu'il faut retenir
- Le test sur slugify révèle 641 entrées identiques entre l'original et la version 'clean room' Malus - les LLM partagent la même mémoire d'entraînement.
- En droit français, le droit moral inaliénable et l'arrêt Edu4 de 2009 rendent la défense clean room IA juridiquement intenable face aux mainteneurs.
- Le risque légal repose entièrement sur l'utilisateur final, pas sur Malus offshore : intégrer ce sujet aux audits M&A et politiques d'achat logiciel.
Résumé généré par IA
Un service américain bien réel propose depuis quelques mois de transformer n’importe quel package open source en code “libéré” de toute obligation de licence, via une clean room peuplée d’agents IA. Une démonstration provocatrice présentée à la conférence FOSDEM 2026 pour forcer un débat que la communauté open source préférerait peut-être éviter. J’ai payé 0,79$ pour tester. Ce que j’ai trouvé en analysant les fichiers livrés éclaire un débat juridique majeur, particulièrement en droit français.

Un service à 0,79$ qui interroge la pérennité de l’open source
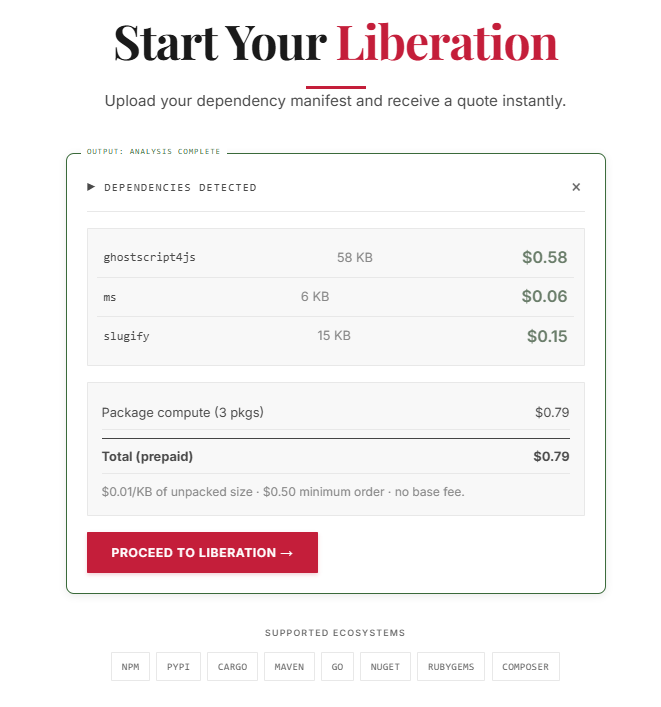
Fin mai 2026, j’ouvre le site malus.sh. Une LLC américaine, un design satirique assumé, un message frontal : “Liberate open source.” Le principe est simple. Tu uploades ton package.json, ils prennent les noms de tes dépendances open source, leurs agents IA recréent le code “from scratch” dans une clean room virtuelle, et tu reçois le résultat sous une licence baptisée MalusCorp-0, sans obligation d’attribution, sans copyleft, sans héritage de licence.
Le service tourne, prend de vrais paiements via Stripe, et compte des clients payants. Pour vérifier, je teste avec trois petits packages : slugify (transformer un texte en URL propre), ms (parser des durées comme “2h30m”) et ghostscript4js (un wrapper Node.js autour de Ghostscript). Devis instantané : 0,79$, calculé à un centime du kilo octet. Je paie.

Quelques minutes plus tard, je reçois un zip. Trois dossiers, du code “libéré”, un dossier de spécifications pour chacun. Je vais maintenant comparer ligne à ligne avec les originaux.
Une provocation calculée plutôt qu’une arnaque
Avant d’examiner ce que Malus livre vraiment, comprenons ce que ses créateurs cherchent à faire. Mike Nolan, chercheur à l’ONU sur l’économie politique des logiciels libres, et Dylan Ayrey, fondateur de Truffle Security, ont présenté Malus.sh à la conférence FOSDEM 2026 à Bruxelles. Le titre de leur talk donnait le ton : Let’s end open source together with this one simple trick.
Leur conviction : si la clean room IA marche vraiment, alors toutes les licences open source qui reposent sur le copyright (MIT, Apache, GPL, AGPL) sont contournables à coût marginal nul. Le copyleft devient symbolique. Nolan a expliqué à 404 Media qui a sorti l’enquête en avril dernier qu’une pure satire aurait été ignorée. En vendant vraiment le service avec un vrai paiement, ils forcent la communauté open source et les régulateurs à prendre le sujet au sérieux. Malus est à la fois une œuvre conceptuelle, une démonstration technique et une provocation politique financée par les clients eux-mêmes.
Cory Doctorow, qui a consacré un long billet au sujet sur Medium, résume bien l’intention : Nolan voulait un coup de semonce pour la communauté du logiciel libre, en démontrant en conditions réelles qu’un risque qu’elle juge théorique est en fait opérationnel et commercialisé.
La question intéressante n’est donc pas “Malus est il honnête ?” mais “Que démontre Malus quand on le teste rigoureusement ?”
Comprendre la clean room originelle : Phoenix Technologies, 1984
Avant d’attaquer le test, il faut comprendre ce qu’est une vraie clean room, parce que tout part de là. Le mot apparaît partout dans le marketing de Malus, et la défense juridique qu’ils invoquent dépend entièrement de ce concept.
La doctrine remonte à un arrêt américain de 1879, Baker v. Selden (101 U.S. 99). La Cour suprême des États-Unis y distingue l’expression d’une idée (protégée par le copyright) et l’idée elle-même (non protégée). Un système comptable, en tant que méthode, ne peut pas être copyrighté. Seule la manière particulière dont l’auteur le décrit l’est. Cette distinction, dite idea/expression dichotomy, est devenue la pierre angulaire de tout le droit du copyright moderne.
En 1984, l’entreprise Phoenix Technologies applique cette doctrine au logiciel pour cloner le BIOS d’IBM. C’est ce moment précis qui rend possible toute l’industrie des PC compatibles qui suit. Voici comment Phoenix s’y est pris, en détail, parce que ces détails sont exactement ce qui rend leur clean room vérifiable et opposable en justice.
Phoenix met en place deux équipes physiquement et contractuellement séparées :
Équipe A, dite “contaminée” : un groupe d’ingénieurs qui ont le droit de lire les manuels techniques IBM et le code source du BIOS. Ils ont environ 8 kilo octets de code IBM à analyser. Leur mission est de produire une spécification fonctionnelle complète, c’est à dire un document texte qui décrit précisément ce que le BIOS fait, sans jamais reproduire le moindre fragment de code. Cette spec est passée en revue par un avocat avant d’être transmise plus loin.
Équipe B, dite “propre” : un second groupe d’ingénieurs sélectionnés pour n’avoir jamais lu les manuels IBM, jamais vu le code source du BIOS. Phoenix pousse même la précaution jusqu’à choisir un programmeur qui n’avait jamais touché aux microprocesseurs Intel auparavant, un développeur TMS9900 préservé de toute contamination. Cette équipe reçoit uniquement la spec produite par l’équipe A. Aucun contact direct entre les deux équipes. À partir de la spec seule, ils réécrivent un BIOS compatible.
La structure est juridiquement défendable parce qu’elle est traçable et vérifiable. Phoenix peut produire des journaux d’accès, des emails internes, des contrats de confidentialité, des déclarations sur l’honneur de chaque membre de l’équipe B. Si un litige éclate, un juge peut faire venir les ingénieurs, examiner leurs antécédents professionnels, vérifier qu’ils n’ont pas eu accès au code IBM. Comme le résume le précédent Apple Computer v. Franklin Computer (1983), qui établit que le firmware est protégé par le copyright : la défense clean room ne tient que si l’isolation est démontrable.
Phoenix commercialise sa licence BIOS en juillet 1984. IBM n’attaque jamais Phoenix. La méthode tient. Pendant les années qui suivent, IBM gagne des millions d’euros en attaquant d’autres cloneurs (Matsushita, Kyocera) qui n’ont pas suivi le protocole clean room. Le critère qui sépare les uns des autres est exactement celui de l’isolation vérifiable.
Voilà la doctrine que Malus.sh prétend appliquer en 2026, mais avec deux agents IA à la place des deux équipes d’ingénieurs. Et c’est précisément là que le bât blesse, comme on va le voir.
Le test : ce que les fichiers livrés racontent vraiment
Le service livre ce qu’il vend. Le zip reçu contient bien du code fonctionnel. Mais en regardant de près ce qu’il y a dedans, plusieurs angles émergent.
Slugify : 641 entrées identiques sur 641
slugify est l’un des packages les plus téléchargés de l’écosystème JavaScript, avec plus de huit millions d’installations par semaine. Sa fonction principale : transformer un texte avec accents et caractères exotiques en URL propre. Pour cela, il s’appuie sur une grosse table de translittération qui mappe chaque caractère Unicode vers son équivalent ASCII.
J’ai comparé la table de mappings de l’original avec celle livrée par Malus. Les chiffres sont parlants.
L’original contient 641 entrées. Le code Malus en contient 641, dans le même ordre exact d’apparition. Sur ces 641 paires clé valeur, 638 sont strictement identiques. Les 3 “différences” restantes sont des artefacts d’échappement de guillemets typographiques, sémantiquement équivalentes.

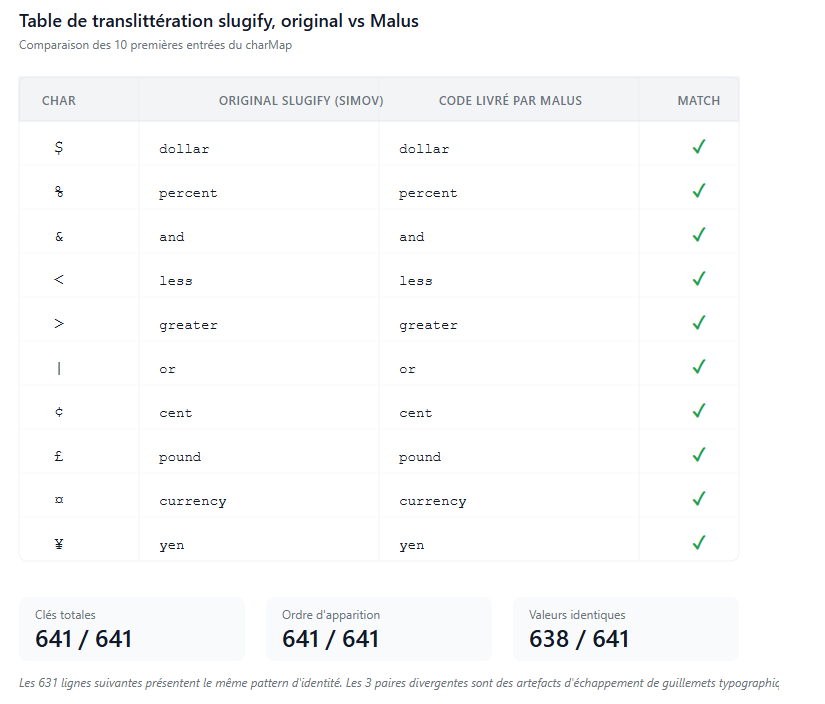
Une vraie clean room aurait dérivé ses mappings depuis les standards Unicode ou la base de données ICU. Elle aurait probablement fait des choix différents sur les caractères ambigus. Le caractère “$” pourrait être mappé vers “USD” ou “dol” plutôt que “dollar”. Le caractère “♥” pourrait devenir “heart” plutôt que “love”. La ligature “Æ” pourrait passer à “ae” plutôt que “AE”. Aucun de ces choix n’a été pris différemment par Malus. Tous correspondent aux choix idiosyncratiques que le mainteneur Simeon Velichkov a faits en 2014 quand il a créé le package.
Plus accablant encore, la regex de filtrage des caractères autorisés est strictement identique au caractère près. La séquence [^\w\s$*_+~.()'"!\-:@]+ est une signature hautement personnelle. L’ordre des symboles dans le set n’est ni alphabétique ni logique, il reflète l’histoire des décisions ad hoc prises par le mainteneur au fil des années.
Pour le dire autrement : il est statistiquement impossible que deux processus indépendants partant uniquement de la documentation publique aboutissent à 641 paires identiques dans le même ordre, avec la même regex idiosyncratique. Le seul scénario plausible est que l’agent Malus a vu le code source original. Et c’est précisément ce que Nolan et Ayrey cherchent à révéler.
L’explication technique tient en une phrase. Les grands modèles de langage comme Claude ou GPT ont ingéré l’intégralité du code public open source pendant leur entraînement. Quand un agent dit “j’écris du code à partir de cette spec”, il pioche aussi dans sa mémoire latente, qui contient le code original. La séparation entre les deux équipes Phoenix de 1984 était physique, contractuelle et vérifiable. La séparation entre les deux agents Malus de 2026 est logique mais pas étanche, parce que les deux agents partagent la même mémoire de pré entraînement. C’est exactement le piège que le développeur Mark Pilgrim avait identifié en mars 2026 sur le package chardet, quand Dan Blanchard avait tenté de le réécrire avec Claude pour le passer de LGPL à MIT puis à 0BSD. Pilgrim avait noté des similitudes de code suspectes malgré le processus de “clean room” annoncé.
MS : un drop in replacement qui diverge en silence
Le deuxième package testé est ms, un petit utilitaire de Vercel qui parse les durées comme “2h30m” en millisecondes et inversement. Je l’ai comparé fonctionnellement avec le code Malus sur vingt-six cas d’usage standards.
Le code Malus diverge sur sept cas. La constante du mois n’est pas la même : Malus utilise 30,44 jours, l’original 30,4375. Cela introduit 216 secondes d’écart par mois, ce qui devient critique sur un TTL de cache ou un système de scheduling. La gestion d’erreur diverge : l’original lance une exception sur chaîne vide, Malus renvoie undefined. Le formatage diverge : pour 604 800 000 millisecondes, l’original renvoie “7d” et Malus renvoie “1w”.
Conséquence pratique : si tu remplaces npm install ms par sa version Malus dans une codebase existante, ton code se met à se comporter différemment, sans erreur visible. Casse silencieuse en production. Pour une entreprise qui utiliserait Malus précisément pour éviter le risque, c’est un coût caché majeur. Ironiquement, ce package est aussi l’illustration que la clean room IA peut produire du code original quand le contenu mémorisé n’est pas assez fort pour dominer la génération.
Ghostscript4js : la clean room qui fonctionne vraiment, et l’attribution qui se perd
Le troisième package est plus exotique. ghostscript4js est un wrapper Node.js qui pilote le binaire natif Ghostscript pour manipuler des PDF. Il pèse 58 kilo octets et fait environ 2 000 téléchargements par semaine, à comparer aux 8 millions de slugify.
Et là, surprise. La comparaison du code C++ entre l’original et la version Malus donne 8 lignes communes sur 697 lignes totales, soit environ 1,1 pour cent de similarité. Architecture différente, choix d’API différents, gestion mémoire différente. Pour ce package précis, la clean room IA a vraiment fonctionné.
L’explication est cohérente avec les findings précédents. ghostscript4js est peu populaire, peu vu pendant l’entraînement des LLMs, donc la mémoire latente du modèle ne contient pas le code et l’agent est forcé de l’inventer depuis la doc. Le pattern qui émerge est limpide : plus un package est populaire, plus la clean room IA produit du code influencé par le source original. Plus un package est obscur, plus la clean room marche vraiment.
Ce package soulève un autre point, plus délicat. L’original ghostscript4js est sous licence Apache 2.0, pas AGPL comme le marketing de Malus le suggère ailleurs. L’Apache 2.0, dans son article 4.b, exige le maintien des copyright notices et des attributions sur toute œuvre dérivée distribuée. Le code livré par Malus a fait disparaître :
- le copyright de Nicola Del Gobbo (auteur, 2017),
- les noms des contributeurs originaux,
- toute mention de la licence Apache.
Le tout livré sous MIT dans le package.json. Si ce code est considéré comme une œuvre dérivée par un juge, c’est une violation de l’Apache 2.0. La défense Malus serait évidente : “ce n’est pas une œuvre dérivée, c’est une réimplémentation indépendante.” Sauf que le cas slugify montre que les agents Malus ne sont pas indépendants.

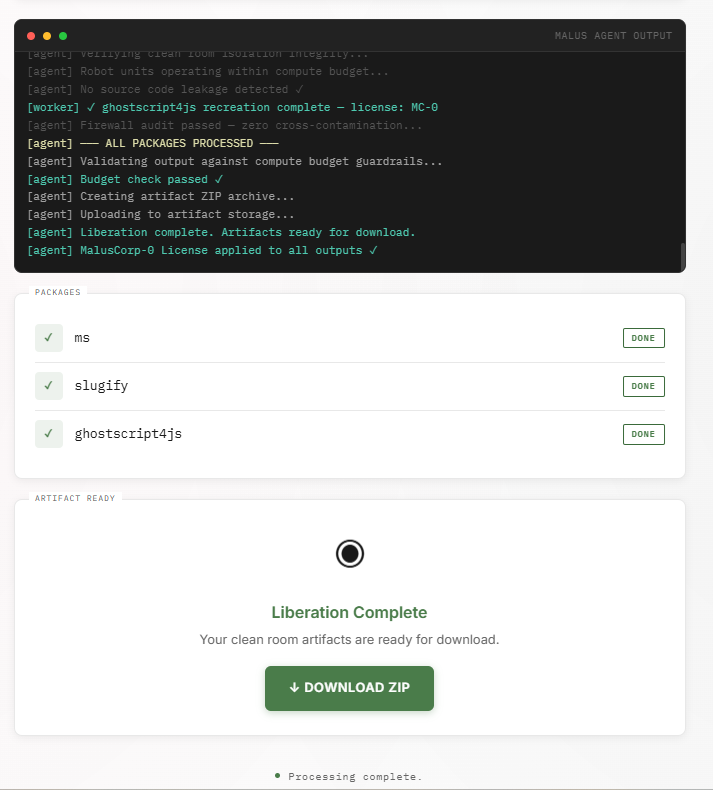
Détail révélateur : la licence MalusCorp-0 n’est pas appliquée
En relisant les package.json livrés, je remarque un autre point. Le terminal du site annonce “MalusCorp-0 License applied to all outputs ✓”. Pourtant les trois packages livrés ont, sans exception, le champ "license": "MIT" dans leurs métadonnées.
Le client paie pour recevoir une licence sans attribution ni copyleft, il reçoit du MIT, qui exige précisément l’attribution. Et l’attribution requise par le MIT serait celle de Malus puisque c’est ce qui figure dans le package.json, pas celle des auteurs originaux qui ont disparu. C’est probablement intentionnel de leur part dans la logique de la démonstration : montrer que même Malus ne sait pas exactement ce qu’il livre est un point politique de plus.
Et en droit français, ça donne quoi ?
La doctrine clean room américaine ne se transpose pas mécaniquement dans le droit français. Le Code de la propriété intellectuelle français est sensiblement plus protecteur que le copyright américain sur deux dimensions clés.
Première dimension, les droits moraux. L’article L121-1 du CPI consacre des droits moraux qui sont inaliénables, perpétuels et imprescriptibles. Même quand un auteur cède ses droits patrimoniaux, son droit moral à la paternité de l’œuvre survit. Concrètement, supprimer le copyright notice de Nicola Del Gobbo sur ghostscript4js pose un problème de droit moral en France indépendamment de ce que l’Apache 2.0 dit aux États-Unis. Cette dimension n’a pas d’équivalent direct en droit américain.
Deuxième dimension, l’opposabilité des licences libres. Et c’est ici que le parallèle devient frappant. Le 16 septembre 2009, la Cour d’appel de Paris a rendu un arrêt qui ressemble étrangement au cas Malus : Edu4 contre AFPA.
Les faits ? La société Edu4 avait livré à l’AFPA un logiciel de prise de contrôle des postes des élèves, construit en intégrant le logiciel libre VNC sous licence GPL. Au lieu de respecter les obligations de la GPL, Edu4 avait :
- intégré une version modifiée de VNC sans le mentionner,
- supprimé les notices de copyright originales de VNC,
- remplacé les copyrights par les siens, prétendant être l’auteur du logiciel,
- supprimé le texte de la licence GPL elle même,
- refusé de fournir les sources modifiées.
Tout ce que Malus fait aujourd’hui à l’échelle d’une plateforme commerciale, Edu4 l’avait fait sur un chantier client en 2001. Saisie par l’AFPA appuyée par la FSF France comme partie sachante, la Cour d’appel de Paris a tranché : Edu4 a violé la GPL, le contrat est résilié, frais de procédure à sa charge. Première décision française à reconnaître pleinement l’opposabilité des licences libres devant les tribunaux. Depuis, la position française est claire : les obligations d’une licence libre sont contractuellement opposables, leur violation est sanctionnable.
Le parallèle avec Malus est saisissant. Si l’arrêt Edu4 disait déjà en 2009 que supprimer le copyright et la licence d’un logiciel sous GPL pour le relicencier sous son nom était une violation, que dira un juge français en 2027 face à Malus qui automatise précisément cette opération sur des centaines de packages ?
Conséquence concrète pour une entreprise française qui envisagerait d’utiliser du code Malus en production. Si un auteur dont le code aurait été ainsi “libéré” attaque devant un tribunal français, le juge n’appliquera pas Baker v. Selden. Il appliquera le CPI, et il aura l’arrêt Edu4 pour précédent. La défense “clean room IA” n’a quant à elle aucun précédent jurisprudentiel français. Le risque légal est entièrement supporté par l’utilisateur final, pas par Malus qui est immatriculé dans une juridiction offshore.
À ma connaissance, aucun avocat IT français n’a encore publiquement pris position sur ces enjeux. Olivier Iteanu, Benjamin Jean (Inno³), Alain Bensoussan, autant de spécialistes français du droit du logiciel libre dont la position serait précieuse à connaître. L’angle est en jachère.
Pour les DSI et CTO français, ce que ça change
Premier point. Malus existe, le service tourne, des entreprises l’utilisent déjà. Que vous le testiez ou non, il faut que ce sujet remonte dans vos politiques d’achat logiciel et dans vos audits de due diligence M&A. Une cible de rachat dont la stack contient du code “libéré” par ce genre de service est une cible à risque légal latent, et l’arrêt Edu4 montre qu’un juge français peut résilier le contrat sur ce motif.
Deuxième point. La promesse marketing de Malus (zéro attribution, zéro copyleft, zéro obligation) n’est pas tenue dans les fichiers livrés. Si vous testez Malus, examinez les package.json reçus avant tout usage. Ils ne contiennent ni la licence MC-0 promise, ni les attributions MIT qu’ils annoncent à la place.
Troisième point. La défense “clean room IA” n’a pas été testée en justice. Aucune cour, aucune juridiction, n’a tranché sur la question de savoir si du code produit par deux agents IA isolés mais entraînés sur le même corpus constitue une œuvre dérivée. Le premier procès qui sortira fera jurisprudence. Personne n’a intérêt à être le défendeur de référence.
Quatrième point. Pour les éditeurs français de logiciel, c’est une menace symétrique. Si une clean room IA marche pour libérer le code des autres, elle marche aussi pour libérer le vôtre. Toute API publique, toute documentation détaillée, toute SDK ouverte peut désormais nourrir un agent IA qui produira un concurrent fonctionnellement équivalent et juridiquement indépendant en quelques minutes. La stratégie de défense devient celle de la rétention d’information sur les internals, ce qui va exactement à l’inverse des bonnes pratiques d’API design [LIEN INTERNE : article ia-insights.fr sur l’agentique ou le GEO si pertinent].
Conclusion : la clean room n’a pas survécu au passage à l’IA
Phoenix Technologies en 1984 séparait physiquement ses ingénieurs, vérifiait leurs antécédents, faisait signer des NDA, conservait les journaux d’accès. Toute cette infrastructure existait pour rendre la clean room opposable en justice. Un juge pouvait, en cas de litige, examiner les preuves et constater l’isolation. C’est cette opposabilité qui a permis l’émergence de toute l’industrie des PC compatibles.
Malus.sh en 2026 prétend faire la même chose avec deux agents IA. Le test à 0,79$ montre que la séparation logique entre l’agent A (qui lit la doc) et l’agent B (qui code à partir de la spec) ne suffit pas. Les deux agents partagent la même mémoire de pré entraînement, qui contient le code original. La clean room IA n’est pas une clean room, c’est une paraphrase pilotée par spec, contaminée par les données d’entraînement du modèle. Les 641 entrées identiques de slugify le démontrent quantitativement.
Mike Nolan et Dylan Ayrey ne croient pas que la fin de l’open source soit souhaitable. Ils croient qu’elle est techniquement possible et qu’il fallait que quelqu’un le prouve en prenant de vrais paiements pour forcer la communauté à prendre le sujet au sérieux. Ma vérification empirique va dans leur sens, mais avec une nuance importante : la clean room IA telle qu’elle existe aujourd’hui ne résisterait probablement pas à un examen juridique sérieux, surtout en droit français.
Le copyright n’est pas mort. Il est en train d’être contourné par des opérateurs qui parient qu’aucun mainteneur n’aura les moyens d’attaquer en justice. Si personne ne les attaque, c’est peut être que la communauté open source française et européenne doit cesser de penser que la GPL et l’AGPL sont des barricades suffisantes. Les barricades intéressantes du futur seront celles qui rendent ce contournement détectable (preuves de copie comme les 641 entrées de slugify), pas celles qui prétendent l’interdire dans l’abstrait.
Nolan voulait ce débat. Il l’a obtenu.
FAQ
Aux États-Unis, le service revendique la doctrine Baker v. Selden qui distingue l’idée et l’expression. Tant qu’aucune cour américaine n’a tranché sur le cas spécifique de la clean room IA, il opère dans une zone grise. En France, le droit moral inaliénable (article L121-1 du CPI) et l’opposabilité des licences libres établie par l’arrêt Edu4 vs AFPA de 2009 rendent la défense beaucoup plus fragile.
Techniquement oui, le code livré fonctionne (avec des bémols comme ceux observés sur ms). Juridiquement c’est très risqué, surtout en droit français. Si tu intègres du code Malus dans un livrable client, tu deviens responsable de la chaîne de licence en cas de litige, pas Malus qui est immatriculé offshore.
Aucune sur le mécanisme technique. Malus industrialise ce que n’importe qui peut faire avec un modèle de pointe et un workflow agentique. La différence est commerciale (Malus prend de l’argent, fait une promesse contractuelle) et démonstrative (Nolan et Ayrey veulent que tout le monde voie le problème).
Non. L’usage analytique et critique entre dans l’exception de citation et de critique du droit français (article L122-5 du CPI). Tant que tu ne mets pas le code en production et que tu attribues les auteurs originaux dans tes citations, tu es protégé.
Aux États-Unis, c’est possible mais coûteux et l’issue est incertaine. En France, oui, l’arrêt Edu4 fournit un précédent solide. Le problème pratique est que la plupart des mainteneurs sont des particuliers ou des petites associations sans budget contentieux. C’est exactement le pari que fait Malus.
Il n’existe pas encore de parade technique. Quelques pistes émergent : limiter la quantité de doc API publique exposée, garder des secrets industriels non documentés dans les internals, ajouter des canary tokens (identifiants spécifiques) dans le code qui ne seraient pas reproductibles depuis la doc seule, surveiller activement les packages cloneurs. Mais la stratégie d’API ouverte et bien documentée, qui est la norme moderne, devient un facteur de risque.
Non, et c’est un résultat important du test. Les packages très populaires (vus massivement pendant l’entraînement des LLMs) sont “libérés” sous forme de copie déguisée. Les packages obscurs bénéficient d’une vraie réécriture. Le risque est paradoxalement plus élevé pour les projets les plus utilisés.
Note méthodologique : tous les chiffres cités proviennent de tests directs réalisés sur le livrable Malus reçu le 26 mai 2026, session Stripe cs_live_a1zepdndIA…. Le code source comparé est celui des dépôts officiels de simov/slugify, vercel/ms et NickNaso/ghostscript4js, clonés depuis GitHub. Méthodologie détaillée et rapports de tests disponibles sur demande.
Sources externes consultées : 404 Media (Emanuel Maiberg, avril 2026), blog de Cory Doctorow sur Medium, Plagiarism Today sur l’AI Washing, FSF France sur l’arrêt Edu4 vs AFPA, Wikipedia Clean-room design, conférence FOSDEM 2026. La position d’avocats IT français spécialisés en droit du logiciel libre reste à recueillir.