


Anthropic vient de lâcher Claude Opus 4.5, et autant le dire tout de suite : c’est un sacré morceau. Après Sonnet 4.5 en septembre et Haiku 4.5 en octobre, voilà le troisième larron de la famille Claude 4 qui débarque avec des ambitions clairement affichées : devenir le modèle de référence pour le développement logiciel et les agents autonomes.
Un modèle qui “comprend juste” ce que tu veux
Ce qui ressort des premiers retours, c’est ce côté “il capte direct”. Les testeurs internes d’Anthropic ont tous dit la même chose : Opus 4.5 gère l’ambiguïté et raisonne sur les compromis sans qu’on ait besoin de lui tenir la main. Tu lui balances un bug complexe qui touche plusieurs systèmes ? Il trouve la solution tout seul.
Le truc intéressant, c’est que les développeurs rapportent que des tâches quasi impossibles avec Sonnet 4.5 il y a quelques semaines deviennent maintenant accessibles. C’est pas juste une amélioration incrémentale, c’est un vrai saut qualitatif.
Les chiffres qui font mal (à la concurrence)
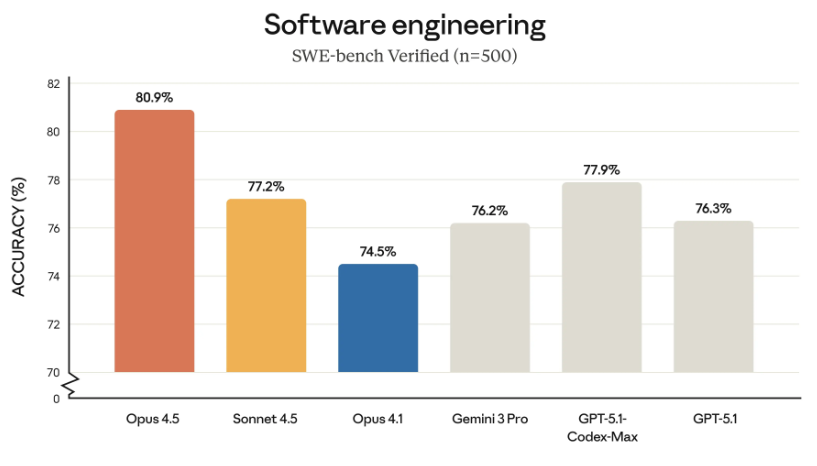
Parlons benchmarks. Sur SWE-bench Verified, le test de référence pour évaluer les capacités de codage des IA, Opus 4.5 affiche 80,9% de réussite. Dans notre classement des meilleurs LLM, Claude Opus 4.5 se positionne en 2ème place avec un Quality Index de 69.8, juste derrière Gemini 3 Pro Preview (72.8) et devant GPT-5.1 (69.7). Une performance solide qui confirme Anthropic dans le top 3 des modèles les plus performants du marché.
Mais le plus impressionnant, c’est l’efficacité. Le modèle accomplit des tâches complexes en utilisant jusqu’à 65% de tokens en moins que les modèles précédents. Moins de tokens = moins de coût = plus de rentabilité pour les projets réels. C’est pas négligeable quand tu fais tourner des agents autonomes 24/7.
Petit test fun : Anthropic a fait passer à Opus 4.5 l’examen technique qu’ils donnent à leurs candidats ingénieurs. Résultat ? Le modèle a obtenu un meilleur score que tous les candidats humains. Bon, il va peut-être falloir revoir le recrutement chez Anthropic… 😅

Tarification premium assumée
Anthropic ne joue pas la carte du low-cost. Opus 4.5 est facturé 5$/million de tokens en entrée et 25$ en sortie. C’est clairement plus cher que GPT-5 (1,25$ et 10$) ou Gemini 2.5 Pro (1,25-2,50$).
Mais leur pari, c’est de dire : “Oui, c’est plus cher à l’appel, mais tu consommes beaucoup moins de tokens pour le même résultat.” En gros, tu payes plus cher le token, mais t’en utilises deux fois moins. L’équation peut être gagnante sur des tâches critiques où la précision compte vraiment.
Et puis, soyons honnêtes : avec les réductions via le prompt caching (jusqu’à 90%) et le batch processing (50%), le prix final peut vite baisser pour une utilisation optimisée.
Claude Code débarque sur desktop
Autre annonce importante : Claude Code arrive enfin en version desktop (Windows, macOS, et même Windows sur ARM64). Jusque-là, c’était limité au mobile et au web.
Claude Code, pour ceux qui connaissent pas, c’est le mode “agent autonome” qui permet de lancer des tâches de développement en arrière-plan. Tu lui files un refactoring massif ou une migration de codebase, et il bosse pendant que tu vas te faire un café (ou que tu mates Netflix, on te juge pas).
Avec Opus 4.5, Claude Code peut maintenant gérer plusieurs sessions en parallèle avec une planification plus structurée. Pratique pour jongler entre plusieurs projets ou pour orchestrer des agents qui collaborent entre eux.
Excel, Chrome et conversations sans limite
Claude continue son expansion dans l’écosystème Microsoft avec Claude for Excel maintenant disponible pour tous les utilisateurs Max, Team et Enterprise. Tu peux analyser, modifier et manipuler des spreadsheets directement avec l’IA.
Claude for Chrome s’ouvre également à plus d’abonnés Max. L’extension permet à Claude d’agir sur plusieurs onglets à la fois, ce qui est super pratique pour automatiser des workflows web.
Petite amélioration bienvenue dans les apps Claude : les longues conversations ne butent plus sur la limite de contexte. Le système résume automatiquement les parties anciennes de la conversation pour libérer de l’espace. Fini le “désolé, la conversation est trop longue” en plein milieu d’un debug complexe.
Pour qui c’est vraiment fait ?
Anthropic cible clairement les développeurs professionnels et les knowledge workers (analystes financiers, consultants, comptables…). Tous ceux qui ont besoin de pousser leur créativité et leurs capacités pros avec un assistant IA ultra-performant.
Le use case idéal ? Les entreprises qui veulent industrialiser l’automatisation documentaire, orchestrer des workflows métiers complexes, ou fiabiliser des processus réglementés. C’est pas pour faire des chatbots basiques, c’est pour des trucs sérieux où l’erreur coûte cher.
La stratégie Anthropic : premium et assumé
Pendant qu’OpenAI et Google essaient de couvrir tous les segments du marché avec des modèles de toutes tailles et tous prix, Anthropic fait le pari inverse. Ils se concentrent sur le haut de gamme, sur les cas d’usage critiques où la précision, la traçabilité et la robustesse sont décisives.
C’est une segmentation du marché qui devient de plus en plus claire : d’un côté, les modèles polyvalents et abordables pour l’usage général. De l’autre, les modèles premium pour les tâches à fort enjeu. Opus 4.5 est clairement dans la deuxième catégorie.
Verdict
Claude Opus 4.5 est probablement le modèle IA le plus impressionnant du moment pour tout ce qui touche au code et aux agents autonomes. Les benchmarks sont solides, les retours utilisateurs sont unanimes, et les capacités avancées (comme le raisonnement hybride avec contrôle fin de l’effort) ouvrent des possibilités inédites.
Le prix premium peut faire tiquer, mais pour des projets où la qualité et la fiabilité sont non-négociables, l’investissement se justifie. Et avec la réduction drastique du nombre de tokens nécessaires, le ROI peut être au rendez-vous sur des workflows complexes.
Anthropic ne cherche pas à être le modèle le moins cher ou le plus rapide. Ils visent le plus capable et le plus fiable. Mission accomplie avec Opus 4.5.
Disponibilité : Claude Opus 4.5 est dispo dès maintenant sur Claude.ai (apps web, iOS, Android), via l’API Claude, et sur les plateformes cloud (Amazon Bedrock, Google Cloud Vertex AI, Microsoft Foundry). Le modèle à utiliser via l’API : claude-opus-4-5-20251101
FAQ
Opus 4.5 est le modèle premium d’Anthropic, conçu pour les tâches les plus complexes (développement logiciel avancé, agents autonomes, workflows critiques). Sonnet 4.5 est le modèle “équilibré” pour un usage quotidien, plus rapide et moins cher. En gros : Opus pour les gros projets où la qualité prime, Sonnet pour la prod et l’usage intensif.
Ça dépend de l’usage. Sur notre classement LLM, Gemini 3 Pro arrive 1er (Quality Index 72.8), Claude Opus 4.5 2ème (69.8) et GPT-5.1 3ème (69.7). Mais sur des benchmarks spécifiques comme SWE-bench Verified (codage), Claude Opus 4.5 domine avec 80,9%. Chaque modèle a ses forces : Gemini pour la polyvalence, Claude pour le code et les agents, GPT pour la vitesse.
Les développeurs pros qui bossent sur des projets complexes, les équipes qui automatisent des workflows critiques, les entreprises avec des processus réglementés où l’erreur coûte cher. Si tu fais juste du chatbot basique ou de la génération de contenu simple, Sonnet 4.5 ou même Haiku 4.5 suffiront largement (et seront moins chers).
Trois options : via les apps Claude (web, iOS, Android) avec un abonnement Pro, Max, Team ou Enterprise, via l’API Claude en utilisant le modèle claude-opus-4-5-20251101, ou via les plateformes cloud (Amazon Bedrock, Google Cloud Vertex AI, Microsoft Foundry). L’accès API est immédiat, pas besoin d’être sur liste d’attente.